
What is Machine Learning?
Máy học là xu hướng phát triển mới của lĩnh vực Trí Tuệ Nhân Tạo và ngày càng có nhiều ứng dụng trong đời sống thực tế. Các ví dụ điển hình của máy học có thể kể đến như cỗ máy tìm kiếm Google. Hằng ngày bạn vào Google tìm kiếm và để ý rằng, Google có thể hiểu được ngữ nghĩa của từ khóa mà bạn tìm kiếm nhằm gợi ý và đưa ra các kết quả tìm kiếm tốt hơn hay gợi ý các kết quả tìm kiếm cho bạn. Hoặc như Facebook, có thể nhận dạng khuôn mặt ở chức năng tag ảnh, có thể gợi ý bài viết liên quan hoặc gợi ý kết bạn. Có khi nào bạn tự hỏi vì sao các ứng dụng có thể “thông minh” đến như thế? Nhờ vào thuật toán cụ thể nào để có thể đạt được như thế?
Bài viết này tôi sẽ chia sẻ về Machine Learning. Để bài viết phong phú, tôi sẽ tổng hợp từ vài nguồn có trên mạng cộng với kiến thức cá nhân về Machine Learning. Hãy bắt đầu nào :)
1. Machine Learning là gì?
Trước tiên đề có cái nhìn tổng quan về Trí Tuệ Nhân Tạo (Artificial Intelligence - AI) hãy nhìn 2 tấm hình bên dưới.
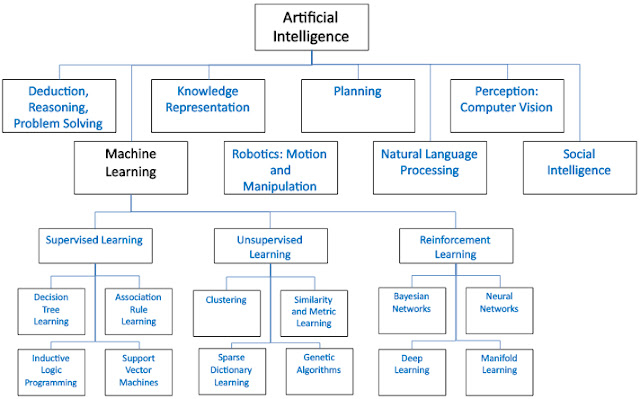
Fig. 1. A Deep Dive in the Venture Landscape of Artificial Intelligence and Machine Learning - September 2015 Ajit Nazre Rahul Garg.

Fig. 2. Machine Learning - http://www.humphreysheil.com/blog/deep-learning-and-machine-learning
Trí Tuệ Nhân Tạo là lĩnh vực rộng nhất của Khoa Học Máy Tính và có rất nhiều nhánh con như: Máy Học, Biểu Diễn Tri Thức và Suy Luận, Xử Lý Ngôn Ngữ Tự Nhiên, Thị Giác Máy Tính… Nói nôm na, AI là giấc mơ của con người nói chung là Khoa Học Máy Tính nói riêng để biến máy tính trở thành cỗ máy có trí thông mình gần giống với con người. Vấn đề này có vẻ khá mơ hồ và ở hiện tại vẫn chưa có cỗ máy nào có khả năng học hỏi được như một đứa bé 5 tuổi. Tuy nhiên, với sự bùng nổ của máy móc và các thuật toán AI, chúng ta hi vọng một ngày không xa sẽ xây dựng được hệ thống thông minh như con người và giúp ích cho cuộc sống (không gây hại là được :3 )
Nhìn vào cả 2 hình, có thể định nghĩa rằng, Máy Học là một nhánh nghiên cứu nhỏ trong lĩnh vực Trí Tuệ Nhân Tạo rộng lớn. Máy học cho phép máy tính có khả năng học hỏi và lấy kinh nghiệm như con người để có thể giải quyết một vấn đề cụ thể nào đó mà con người khó có thể làm được. Máy Học là một phương pháp phân tích dữ liệu mà sẽ tự động hóa việc xây dựng mô hình phân tích. Sử dụng các thuật toán lặp để học từ dữ liệu, Máy Học cho phép máy tính tìm thấy những thông tin giá trị ẩn sâu mà không được lập trình một cách rõ ràng.[1] Nói cách khác, các mô hình Máy Học chủ yếu dựa vào thống kê vì lượng dữ liệu để huấn luyện rất lớn và chắc chắn không có một đoạn code cụ thể nào để giải quyết (hard code) nên ta hi vọng máy tính có thể giải quyết chín xác bao nhiêu phần trăm bài toán (độ chín xác). Và đương nhiên kỳ vọng càng chín xác càng tốt.
Có 2 định nghĩa khá rõ ràng về Machine Learning như sau: Theo Arthur Samuel (1959): Máy học là ngành học cung cấp cho máy tính khả năng học hỏi mà không cần được lập trình một cách rõ ràng. Theo Giáo sư Tom Mitchell - Carnegie Mellon University thì Machine Learning là: Một chương trình máy tính được nói là học hỏi từ kinh nghiệm E từ các tác vụ T và với độ đo hiệu suất P. Nếu hiệu suất của nó áp dụng trên tác vụ T và được đo lường bởi độ đo P tăng từ kinh nghiệm E. (Có vẻ hơi khó hiểu khi đọc lần đầu !!! Xuống phần ví dụ để rõ hơn xíu)
Ví dụ cho định nghĩa của Tom Mitchell
Ví dụ 1: Giả sử như bạn muốn máy tính xác định một tin nhắn có phải là SPAM hay không? Thì tác vụ T lúc này sẽ là: Xác định 1 tin nhắn có phải SPAM hay không?
Kinh nghiệm E: Xem lại những tin nhắn đánh dấu là SPAM xem có những đặc tính gì để có thể xác định nó là SPAM.
Độ đo P: Là phần trăm số tin nhắn SPAM được phân loại đúng.
Ví dụ 2: Chương trình nhận dạng số (số từ 0 -> 9) T: Là nhận dạng được ảnh chứa ký tự số. E: Đặc trưng để phân loại ký tự số từ tập dữ liệu số cho trước. P: Độ chín xác của quá trình nhận dạng.
2. Các dạng Máy Học.
Máy học được phân làm 3 loại chính là: Học có giám sát (Supervised learning), học không giám sát (Unsupervised learning), học tăng cường (Reinforcement learning). Trong đó phổ biến nhất là 2 loại Supervised learning và Unsupervised learning. Riêng học tăng cường là một loại cải tiến từ các mô hình của học có giám sát. Phần này sẽ giới thiệu về khái niệm và ứng dụng của Supervised learning và Unsupervised learning.
Supervised Learning
- Định nghĩa:
Supervised Learning (SL) là một kĩ thuật học máy để học tập từ tập dữ liệu được gán nhãn cho trước. Tập dữ liệu cho trước sẽ chứa nhiều bộ dữ liệu. Mỗi bộ dữ liệu có cấu trúc theo cặp {x, y} với x được xem là dữ liệu thô (raw data) và y là nhãn của dữ liệu đó. Nhiệm vụ của SL là dự đoán đầu ra mong muốn dựa vào giá trị đầu vào. Dễ nhận ra, học có GIÁM SÁT tức là máy học dựa vào sự trợ giúp của con người, hay nói cách khác con người dạy cho máy học và giá trị đầu ra mong muốn được định trước bởi con người. Tập dữ liệu huấn luyện hoàn toàn được gán nhãn dựa vào con người. Tập càng nhỏ thì máy tính học càng ít.
SL cũng được áp dụng cho 2 nhóm bài toán chính là bài toán dự đoán (regression problem) và bài toán phân lớp (classification problem).
Kỹ thuật SL thực chất là để xây dựng một hàm có thể xuất ra giá trị đầu ra tương ứng với tập dữ liệu. Ta gọi hàm này là hàm h(x) và mong muốn hàm này xuất ra đúng giá trị y với một hoặc nhiều tập dữ liệu mới khác với dữ liệu được học. Hàm h(x) cần các loại tham số học khác nhau tùy thuộc với nhiều bài toán khác nhau. Việc học từ tập dữ liệu (training) cũng chính là tìm ra bộ tham số học cho hàm h(x).
- Ứng dụng:
Các ứng dụng của SL có thể kể đến tương ứng với 2 dạng bài toán nêu trên như sau:
Bài toán dự đoán (regression problem): Bài toán dự đoán sẽ có đầu ra là một giá trị liên tục. Ví dụ: Bài toán dự đoán giá nhà, dự đoán xu hướng giá xăng, dự báo thời tiết….
Xét cụ thể bài toán dự báo giá nhà. Hãy đặt câu hỏi, đầu vào của bài toán và đầu ra của bài toán là gì?
Đầu vào là thông tin về nhà (diện tích, số phòng ngủ, gần đường hay không?, v.v..) và đầu ra là giá của ngôi nhà.
Tập dữ liệu để huấn luyện ở đây là thông tin có sẵn về nhà và giá của nó (có thể tự đi khảo sát để lấy thông tin hoặc dựa vào internet). Vì giá nhà là giá trị không thống nhất, có thể có nhiều giá trị thay đổi (giá trị liên tục) nên ta nói đây là bài toán dự báo.
Bài toán phân lớp (classification): Bài toán phân lớp sẽ có kết quả đầu ra cụ thể là các lớp được cho trước. Ví dụ bài toán nhận dạng ký tự số, bài toán phát hiện tin nhắn SPAM…
Xét cụ thể bài toán nhận dạng ký tự số thì khác với bài toán dự báo giá nhà, đầu ra của bài toán nhận dạng ký tự số chỉ là 10 lớp tương ứng với 10 số (từ 0 - 9). Các giá trị này là giá trị rời rạc.
Tập dữ liệu cũng tương tự như trên bài toán dự đoán, tuy nhiên giá trị đầu ra sẽ bị giới hạn bởi giá trị của các lớp cần phân loại. Trong trường hợp này y thuộc {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
Unsupervised Learning
- Định nghĩa:
Unsupervised Learning (UL) là một kĩ thuật của máy học nhằm tìm ra một mô hình hay cấu trúc bị ẩn bơi tập dữ liệu KHÔNG được gán nhãn cho trước. UL khác với SL là không thể xác định trước output từ tập dữ liệu huấn luyện được. Tùy thuộc vào tập huấn luyện kết quả output sẽ khác nhau. Trái ngược với SL, tập dữ liệu huấn luyện của UL không do con người gán nhãn, máy tính sẽ phải tự học hoàn toàn. Có thể nói, học KHÔNG GIÁM SÁT thì giá trị đầu ra sẽ phụ thuộc vào thuật toán UL.
- Ứng dụng:
Ứng dụng phổ biến nhất của học không giám sát là gom cụm (cluster). Đương nhiên sẽ có nhiều ứng dụng khác, có cơ hội tôi sẽ đề cập thêm.
Ứng dụng này dễ nhận ra nhất là Google và Facbook. Google có thể gom nhóm các bài báo có nội dung gần nhau, hoặc Facebook có thể gợi ý kết bạn có nhiều bạn chung cho bạn.
Các bài báo có cùng nội dung sẽ được gom lại thành một nhóm (cluster) phân biệt với các nhóm khác. Dữ liệu huấn luyện là các bài báo từ quá khứ tới hiện tại và tăng dần theo thời gian. Dễ nhận ra rằng dữ liệu không thể gán nhãn bởi con người :)
Khi một bài báo mới được cho vào input, nó sẽ tìm cụm (cluster) gần nhất với bài báo đó và gợi ý những bài liên quan.
3. Máy Học và các ứng dụng thực tế.
Có rất nhiều ứng dụng mang tính thực tế cao của máy học mà khó có thể kể hết được. Những ứng dụng dưới đây là những ứng dụng phổ biến và được chọn lọc theo góc nhìn cá nhân. Hi vọng có thể truyền cảm hứng thêm cho đọc giả.
- Nhận diện và phát hiện khuôn mặt: Nhận diện và phát hiện khuôn mặt là ứng dụng khá thú vị của máy học và được áp dụng khá nhiều vào đời sống. Tiêu biểu là tính năng phát hiện khuôn mặt ở máy chụp ảnh. Ứng dụng được phát triển thêm thành phát hiện chớp mắt, phát hiện cười….
- Xe tự lái: Xe tự lái mặc dù phát triển từ đầu thập niên 90 nhưng cho tới nay vẫn còn là vấn đề được nhiều người quan tâm. Các hãng lớn như Google, NVDIA đang nỗ lực để tạo ra một cỗ máy có thể hoàn toàn tự động lái xe và giảm thiểu tai nạn cho con người.
- Phân lớp ảnh: Tìm kiếm ảnh trên Google hiện rất quen thuộc với nhiều người. Ứng dụng của phân lớp ảnh giúp người dùng sử dụng ảnh làm từ khóa tìm kiếm thay thế cho việc tìm kiếm truyền thống trên Google. Bạn upload một ảnh lên và Google sẽ giúp bạn tìm kiếm những thông tin liên quan đến bức ảnh đó.
- Nhận dạng giọng nói: Các trợ lý ảo như Siri, Conrtana hay Google Now là ví dụ điển hình cho nhận dạng giọng nói. Một ví dụ khác nữa là tính năng dịch thuật trực tuyến của Youtube. Với ứng dụng của Deep Learning, khả năng dịch thuật chín xác ngôn ngữ từ các video Youtube đang ngày một phát triển vượt bậc.
- Anti-virus: Có thể nhiều người không nghĩ rằng các phần mềm diệt virus lại áp dụng máy học. Tuy nhiên, áp dụng máy học vào để phân tích và dự đoán xu hướng các loại virus sẽ giúp ích rất nhiều trong việc bảo vệ dữ liệu máy tính.
Còn rất rất nhiều ứng dụng thực tế của máy học nữa. Mong rằng bài viết này sẽ giúp các bạn hiểu hơn về Máy Học. Chúc các bạn thành công.
4. Nguồn trích dẫn
[1] Machine Learning là gì và tại sao nó lại quan trọng? - https://techmaster.vn/posts/33836/machine-learning-la-gi-tai-sao-machine-learning-lai-quan-trong
[2] Machine Learning Course by Andrew Ng - https://www.coursera.org/learn/machine-learning
[3] Machine Learning - https://en.wikipedia.org/wiki/Machine_learning