
Building a simple SUDOKU Solver from scratch - Part 1: Grid Detection & Digit Extraction
Hi, today I’m gonna explain how to build a simple SUDOKU Solver taken from image step-by-step. You can see the demo of SUDOKU Solver in the GIF image below.
To build this program, we will go through 4 main steps.
1. SUDOKU Grid Detection and Digit Extraction
2. Recognize Number with Support Vector Machine (SVM)
3. Solving SUDOKU with Backtracking Algorithm
4. Completing the simple SUDOKU Solver
This program was built by Python 2.7 and OpenCV 2.4.13 so before you want to follow this post, please install Python 2.7 and OpenCV 2.4.13 Update: Since some people asked me to modify the code to work with OpenCV 3.x, please refer to this link if you’re using OpenCV 3.x SUDOKU_OpenCV3
1. SUDOKU Gird Detection and Digit Extraction
The most important thing to solve a SUDOKU board from images is detecting SUDOKU grid (or line). I found many ways to extract digit from SUDOKU on the internet, but I saw this article (http://jponttuset.cat/solving-sudokus-like-a-pro-1/) is the smartest and easy way to extract digit from SUDOKU board. I took the idea from that guy and re-implement myself with Python. Let’s get started!
We will use a famous and simple technique called Hough Line Transform to detect lines on the image. If you’re not familiar with Hough Line Transform, please check out my previous article about Hough Line Transform
Note: We can visit this website to print any SUDOKU images for practicing: http://show.websudoku.com/
From an RGB frame captured from the webcam, we will convert it to a grayscale image. After that, extract edges using Canny Edge detection and then apply Hough Line Transform to detect lines. We use cv2.HoughLines() with \(\rho\) unit equal to \(2\) and minimum length of line to be detected is \(300\) pixels. It means increasing the accumulator by \(2\) when a point is satisfied and consider to be a line when the minimum value in the accumulator is \(300\). The result will look like this:

Fig. 1. Line detection using Hough Line Transform
The next step is looking for intersections between these lines. When we know the intersection points, we can extract every block that contains SUDOKU digit.
Hmm … Look at that! There are too many lines. Synonymous with there are some redundant lines (some lines are overlapped each other).
But wait, we already know the distance of each line to the origin. It means we can easily remove the overlapped lines if the distance between these lines is close to each other.
Let’s say we will remove the redundant lines if the distance between these lines is less than \(10\).
Firstly, let’s sort these line increasingly by the distance (\(\rho\)) and then check the distance of every \(2\) lines. If the distance is less than \(10\), remove the second line.
You can read the following code
# HOW TO USE # Use this with a printed SUDOKU Grid # Press ESC key to Exit import cv2 import numpy as np ratio2 = 3 kernel_size = 3 lowThreshold = 30 cv2.namedWindow("SUDOKU Solver") vc = cv2.VideoCapture(0) if vc.isOpened(): # try to get the first frame rval, frame = vc.read() else: rval = False while rval: # Preprocess image, convert from RGB to Gray sudoku1 = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) sudoku1 = cv2.blur(sudoku1, (3,3)) # Apply Canny edge detection edges = cv2.Canny(sudoku1, lowThreshold, lowThreshold*ratio2, kernel_size) # Apply Hough Line Transform, return a list of rho and theta lines = cv2.HoughLines(edges, 2, cv2.cv.CV_PI /180, 300, 0, 0) if (lines is not None): lines = lines[0] lines = sorted(lines, key=lambda line:line[0]) # Define the position of horizontal and vertical line pos_hori = 0 pos_vert = 0 for rho,theta in lines: a = np.cos(theta) b = np.sin(theta) x0 = a*rho y0 = b*rho x1 = int(x0 + 1000*(-b)) y1 = int(y0 + 1000*(a)) x2 = int(x0 - 1000*(-b)) y2 = int(y0 - 1000*(a)) # If b > 0.5, the angle must be greater than 45 degree # so we consider that line as a vertical line if (b>0.5): # Check the position if(rho-pos_hori>10): # Update the position pos_hori=rho cv2.line(frame,(x1,y1),(x2,y2),(0,0,255),2) else: if(rho-pos_vert>10): pos_vert=rho cv2.line(frame,(x1,y1),(x2,y2),(0,0,255),2) # Show the result cv2.imshow("SUDOKU Solver", frame) rval, frame = vc.read() key = cv2.waitKey(20) if key == 27: # exit on ESC break vc.release() cv2.destroyAllWindows()
Now, the result looks better than before.
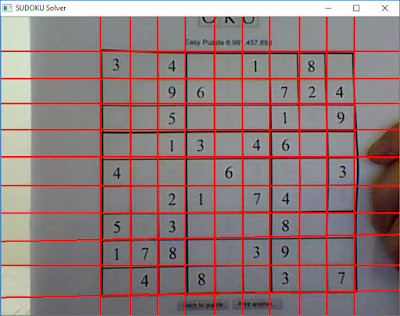
Fig. 2. SUDOKU Grid after removing redundancy lines
Next, we will find the intersection points based on those lines. Just to recap again, every line is satisfied this equation: \(\rho=x\cos \theta+y\sin \theta\) (1)
We have \(\rho\) and \(\theta\) for each line, so it’s easy to find the intersection between 2 lines by solving linear equations. In this post, I use the \(linalg\) library in Numpy to find the intersection points.
You can check out this link to see how to use \(linalg\) in Python: https://docs.scipy.org/doc/numpy/reference/generated/numpy.linalg.solve.html
Just change a bit of code and found the intersection points like this

Fig. 3. Intersection points detection
If we have those points, we also can extract the bouding boxes of the digit number in the SUDOKU board.

Fig. 4. Bounding block for each digit
Here is the code for digit number extraction
# HOW TO USE # Use this with a printed SUDOKU Grid # Press ESC key to Exit import cv2 import numpy as np ratio2 = 3 kernel_size = 3 lowThreshold = 30 cv2.namedWindow("SUDOKU Solver") vc = cv2.VideoCapture(0) if vc.isOpened(): # try to get the first frame rval, frame = vc.read() else: rval = False while rval: # Preprocess image, convert from RGB to Gray sudoku1 = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) sudoku1 = cv2.blur(sudoku1, (3,3)) # Apply Canny edge detection edges = cv2.Canny(sudoku1, lowThreshold, lowThreshold*ratio2, kernel_size) # Apply Hough Line Transform, return a list of rho and theta lines = cv2.HoughLines(edges, 2, cv2.cv.CV_PI /180, 300, 0, 0) if (lines is not None): lines = lines[0] lines = sorted(lines, key=lambda line:line[0]) # Define the position of horizontal and vertical line pos_hori = 0 pos_vert = 0 # Create a list to store new bundle of lines New_lines = [] # Store intersection points Points = [] for rho,theta in lines: a = np.cos(theta) b = np.sin(theta) x0 = a*rho y0 = b*rho x1 = int(x0 + 1000*(-b)) y1 = int(y0 + 1000*(a)) x2 = int(x0 - 1000*(-b)) y2 = int(y0 - 1000*(a)) # If b > 0.5, the angle must be greater than 45 degree # so we consider that line as a vertical line if (b>0.5): # Check the position if(rho-pos_hori>10): # Update the position pos_hori=rho # Saving new line, 0 is horizontal line, 1 is vertical line New_lines.append([rho,theta, 0]) else: if(rho-pos_vert>10): pos_vert=rho New_lines.append([rho,theta, 1]) for i in range(len(New_lines)): if(New_lines[i][2] == 0): for j in range(len(New_lines)): if (New_lines[j][2]==1): theta1=New_lines[i][1] theta2=New_lines[j][1] p1=New_lines[i][0] p2=New_lines[j][0] xy = np.array([[np.cos(theta1), np.sin(theta1)], [np.cos(theta2), np.sin(theta2)]]) p = np.array([p1,p2]) res = np.linalg.solve(xy, p) Points.append(res) if(len(Points)==100): sudoku1 = cv2.adaptiveThreshold(sudoku1, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY_INV, 101, 1) for i in range(0,9): for j in range(0,9): y1=int(Points[j+i*10][1]+5) y2=int(Points[j+i*10+11][1]-5) x1=int(Points[j+i*10][0]+5) x2=int(Points[j+i*10+11][0]-5) # Saving extracted block for training, uncomment for saving digit blocks # cv2.imwrite(str((i+1)*(j+1))+".jpg", sudoku1[y1: y2, # x1: x2]) cv2.rectangle(frame,(x1,y1), (x2, y2),(0,255,0),2) # Show the result cv2.imshow("SUDOKU Solver", frame) rval, frame = vc.read() key = cv2.waitKey(20) if key == 27: # exit on ESC break vc.release() cv2.destroyAllWindows()
To make sure that we extract the correct digit blocks, I set the condition which when the number of intersection points is equal to 100, we start to extract the digits. You can check out the above code.
Bravo! Now we know how to extract digit number block from SUDOKU board. In the next article, we will recognize those digit numbers with Support Vector Machine algorithm :)